同期のベストプラクティス (AWS と PPO モデルのみ)
AWS および PPO モデルには、Spark 上で実行されるより堅牢な計算エンジンがあります。Spark が計算を実行するには、データベース サーバー間で 2 種類の同期が行われます。詳細は以下を参照してください。
比較チャート
同期転送
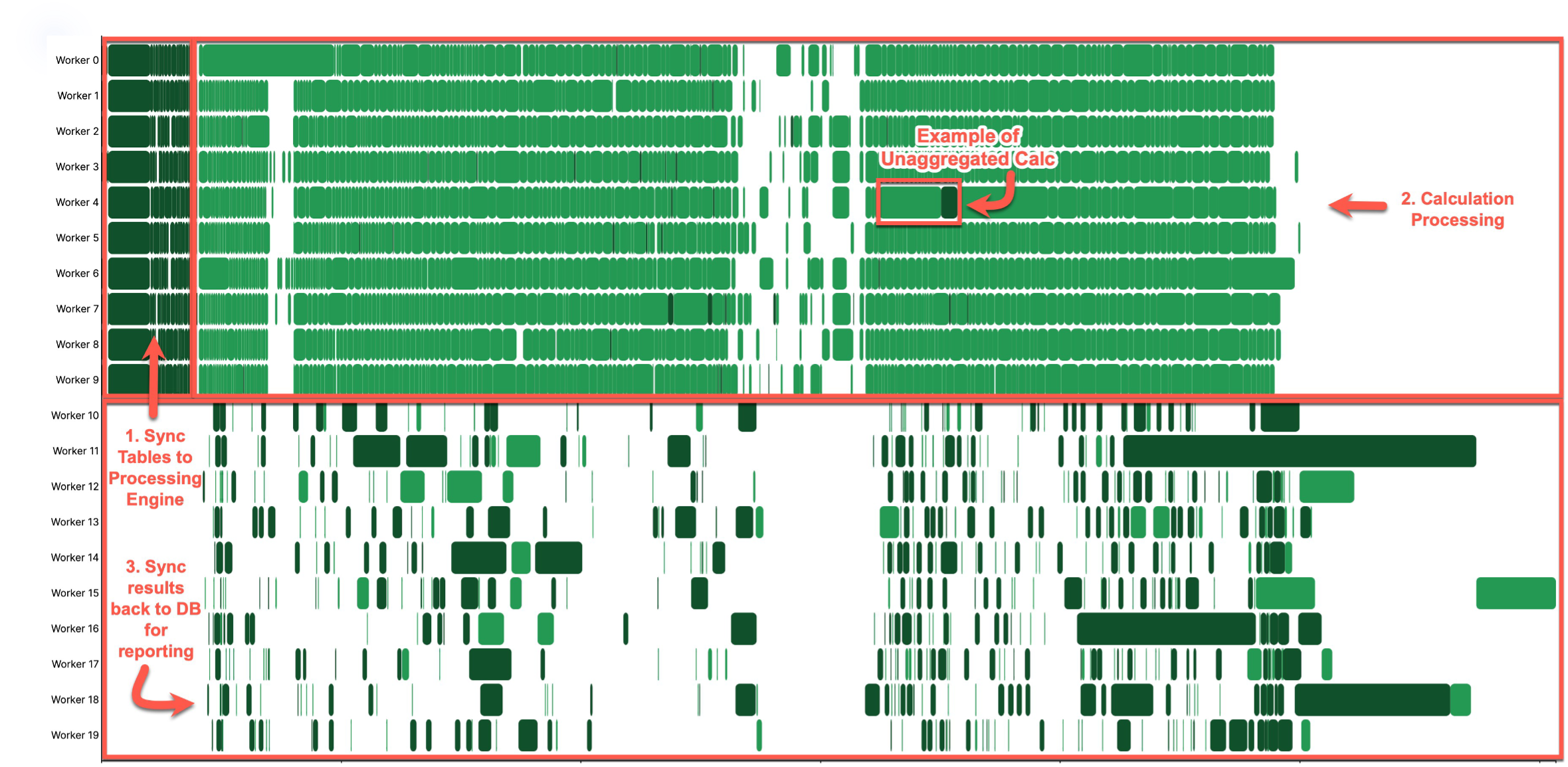
計算が開始されると、Varicent テーブルにロードされたすべての新規データは、S3 (AWS) または COS (IBM) のいずれかに同期されます。これは、Spark が計算を処理するストレージ レイヤーです。これは、上の画像のステップ 1 として示されています。
注記
モデルを新しい環境に復元するときの最初の計算では、すべてのデータを初期化する必要があり、大規模なモデルでは時間がかかる場合があります。後続の計算は増分的に同期されるため、はるかに高速になります。
同期バック
Spark が計算結果を処理している間、一部の結果は DB サーバーに同期されます。これは、上の画像のステップ 3 として示されています。この例のワーカー 10 ~ 19 は同期スレッドですが、0 ~ 9 は実際の計算スレッドです。
次のオブジェクトは計算を強制的に同期します:
計算に使用されるもの:
レポート
出版物
データストアとビュー
レポート データ モデル (RDM)
カレンダーをロックすると、そのカレンダーを使用するすべての計算が、ロックされている期間にわたって DB サーバーに同期されます。
同期時間を短縮するためのベストプラクティス:
できるだけ頻繁にロックするようにしてください。ロックされた結果は、通常の処理中に同期する必要がなくなります。
同期をトリガーする可能性のある未使用のオブジェクトをクリーンアップします (例: どのレポートでも使用されていないデータ ストア)
計算が追加のフィルタリングを持つビューまたはデータ ストアにフィードされる場合は、最初にフィルタリングを実行する新しい計算を作成することを検討してください。例:
Calc A は同期に 20 分かかり、1 億行を生成します。
Calc A は、1 億行を現在の月にフィルターするビューでのみ使用されます。
Calc A を現在の月にフィルターする新しい計算を作成し、ビュー ソースを新しい計算に置き換えます。これにより、Calc A を同期する必要がなくなり、より小さい現在の月の計算のみが同期されます。
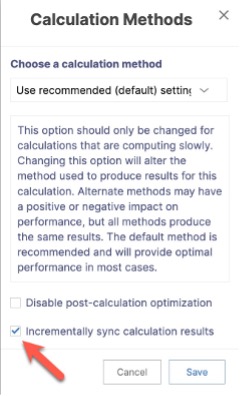
同期に 10 分以上かかる計算の場合は、「増分同期」オプションの使用を検討してください。このオプションはクエリに若干のオーバーヘッドを追加しますが、前回の実行からの差分を識別し、必要な変更のみを同期します。このオプションは、毎日変更される行数がそれほど多くない計算に特に有効です。これは、計算をクリックしてコンテキスト メニューで「計算方法の選択」を選択することで、個々の計算レベルで設定できます。ポップアップには、「計算結果を増分同期」オプションがあります。